
Kafka Connect: How to create a real time data pipeline using Change Data Capture (CDC)
Microservices, Machine Learning & Big Data are making waves among organizations. Curiously they all share the same biggest concern: data.
In today’s fast-moving world, where immediacy of information is no longer nice-to-have, but absolutely critical for business competitiveness and survival, ETL processes that run on periodic basis are no longer the best option. Real-time (or near real-time) alternatives such as streaming provide a way of processing big volumes of data while allowing to instantly react to changing conditions, but sometimes at an expense of having tons of people dedicated to build an infrastructure capable of doing so while addressing issues like fault tolerance, performance, scalability and reliability. Therefore we’ll go through a way of doing it without even having to write a single line of code.
Introducing Kafka Connect
You should know by now that most companies use databases to keep track of their data. What you may not know is that most database management systems manage an internal transaction log that records changes over time. By scanning and interpreting the transaction log, one can capture the changes made to the database in a non-intrusive manner. This is known as Change Data Capture (CDC) and can be useful for several purposes:
- ETL and Data Warehousing;
- Data Lake Ingestion;
- Streaming;
- Data propagation, replication, synchronisation and/or migration;
- Moving from monolithic applications to microservices;
- Event-driven architecture.
So, why use Kafka Connect? Basically, Kafka Connect allows to monitor a database, capture its changes and record them in one or more Kafka topics (typically one topic per database table). Plus, by saving it on Kafka it ensures that data is replicated, totally ordered and available in an asynchronous way to multiple consumers:

Building our pipeline
The use case that we’ll be following consists in a small bike store that saves data about customers, products and orders in a relational database:

Now, let’s imagine that, for some reason, this store needs to share part of its data to a third-party client which is operating on a bigger scale. Let’s also assume that this client doesn’t rely only on relational databases. Data is in fact being replicated in multiple instances and is supported by different technologies with distinct purposes (analytics, searching, machine learning, etc). This setup creates multiple challenges:
- How to share data without giving source access to third-parties?
- How to share data without compromising performance?
- How to share data to multiple consumers at the same time?
- Most importantly, how to do it in real-time?
So, let’s dig into it. The main goal is to capture database events and send them to Kafka so they can be consumed in real time or afterwards. This implies having the database populated and the infrastructure up and running. In order to do so we’ll use the following open-source technologies:
- Docker — Tool to create, deploy and run applications by using containers;
- Apache Kafka — Distributed streaming platform which allows to publish and subscribe to streams of messages (similar to a message queue or enterprise messaging system) in a fault-tolerant durable way;
- Apache Kafka Connect — Kafka’s API that allows to implement connectors that continually pull from some source data system into Kafka or push from Kafka into some sink data system;
- Apache Zookeeper — Centralised service which enables highly reliable distributed coordination between Kafka instances;
- PostgreSQL — Relational database;
- Debezium’s PostgreSQL Connector — Low latency data streaming connector that can monitor and record row-level changes in PostgreSQL.
Since we’re going to use Docker, you won’t have to spend much time installing and configuring every piece of software on this list. This is specially important because it allows us to set up our infrastructure really fast in an isolated environment. However, if you don’t have Docker yet, you’ll have to download it and follow install instructions depending on your operating system.
Moving on, we’ll start by creating a Docker Compose that manages two services. The first one is our database running an image of PostgreSQL provided by Debezium. This image is based upon PostgreSQL 12 and adds a Debezium-specific logical decoding output plugin enabling to capture changes committed to the database. The second one is our message broker running an image of Kafka provided by Landoop. This image allows to set a full fledged Kafka installation on top of Zookeeper which already includes Kafka Connect and Confluent Schema Registry. You can find the final YAML file below:
You may have noticed that we’re starting our database container with a volume. This volume is used to mount two files on this container which then are going to be used as initialization scripts. This is important, because not only it allows us to provide an initial state by creating and seeding our tables, but also it allows Debezium’s plugin to perform an initial snapshot of our database. Just don’t forget to download both files and change volume’s mount source to your local folder.
Next, just change your directory to the folder where you’ve downloaded your docker-compose.yml file and set everything up by running:
$ docker-compose up -dAfter a few seconds, both containers should be running and our bike store database should be populated. You can ensure that by running:
List running containers:
$ docker ps -f network=bike-store-networkRead logs from database container:
$ docker logs bike-store-postgres
At this moment it should be possible to access Kafka Development Environment UI. This UI allows to get relevant information about schemas (messages’ data model description), topics (place where messages are published) and connectors (components used to import/export data to/from Kafka). The main page should look as follows:
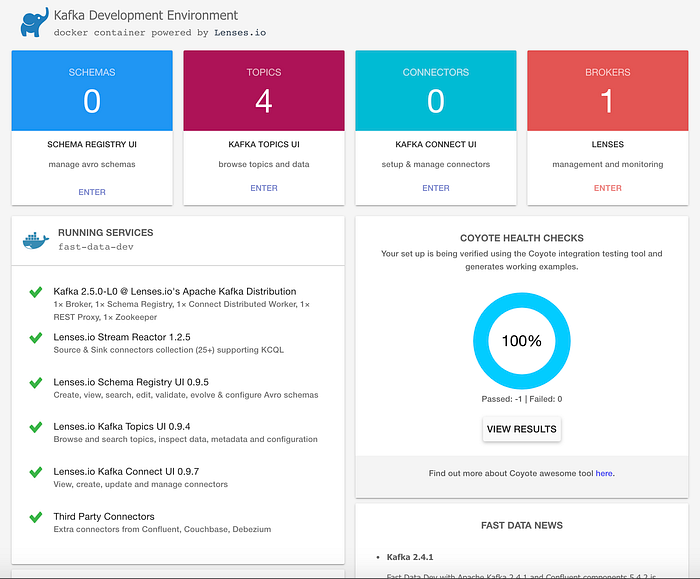
By default, four system topics are created automatically. They are used to save not only schema and connector configurations, but also connector offsets and status, so no need to worry about managing this settings.
The next step is to create a Kafka Connect source connector. In order to do so just use Kafka Connect UI. After accessing it, press “New” and choose “PostgresConnector” from the available options. This connector is in fact Debezium’s PostgreSQL Connector, so just go ahead and copy and paste the following properties:
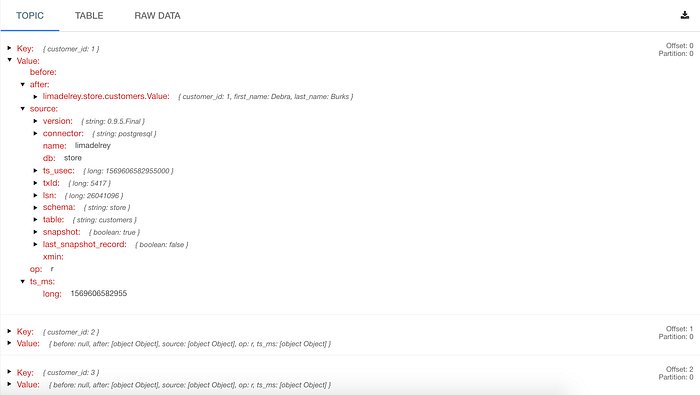
The source connector properties are pretty self-explanatory. Given a PostgreSQL instance and its credentials, the connector is able to consume every message generated from the whitelisted tables just by listening to the database transaction log. Since the database is already populated, the connector performs an initial snapshot of the database, creating a topic for each table automatically with every single message ever recorded:

These topics are divided in partitions and each partition is placed on a separate broker. They keep data in the cluster until a configurable period has passed by and they are replicated for backup and high availability purposes. This is especially important because it allows to keep subscribing more consumers while maintaining data over time. Regarding data, every message produced by Debezium’s connector has a key and a value. The message’s key holds the value of the table’s primary key (which allows to track all changes made to a row as a sequence of events) while the message’s value holds the remaining fields in its previous and current state, plus additional metadata about the message generation following a format that is conveniently defined by Debezium with the following fields:
beforeis an optional field that if present contains the state of the row before the event occurred;afteris also an optional field that if present contains the state of the row after the event occurred;sourceis a mandatory field that contains a structure describing the source metadata for the event (e.g. Debezium’s version, connector name, the name of the affected database, schema, table, etc);opis another mandatory field that describes the type of operation;ts_msis optional and if present contains the time at which the connector processed the event.
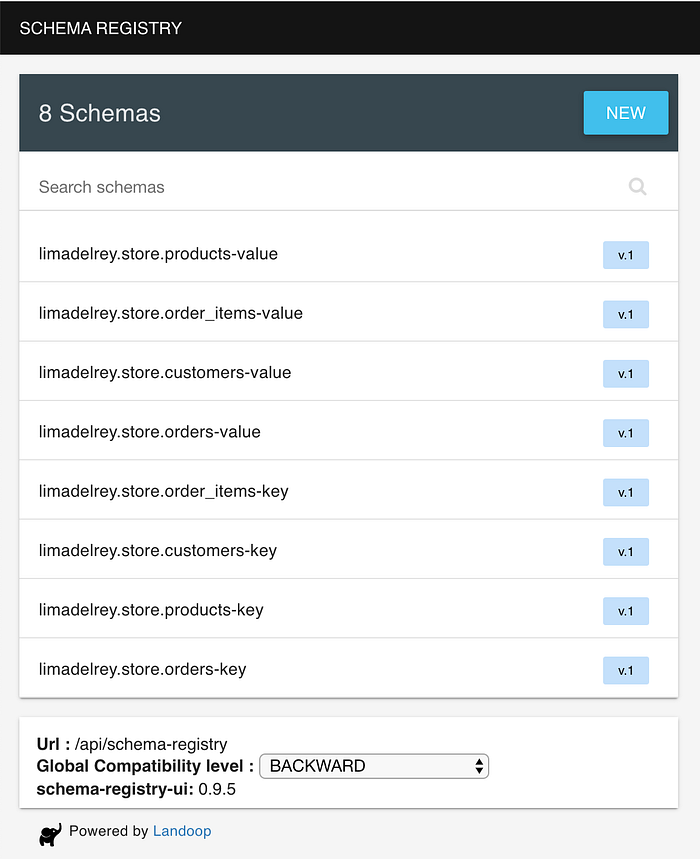
Alongside with topic creation, the source connector also creates an AVRO schema for each message key and each message value which allows to enforce the format presented previously. AVRO schemas are very popular in data serialisation because they allow to adopt a data format and enforce rules that enable schema evolution while guaranteeing not to break downstream applications:
Finally, Kafka Development Environment UI should look as follows:
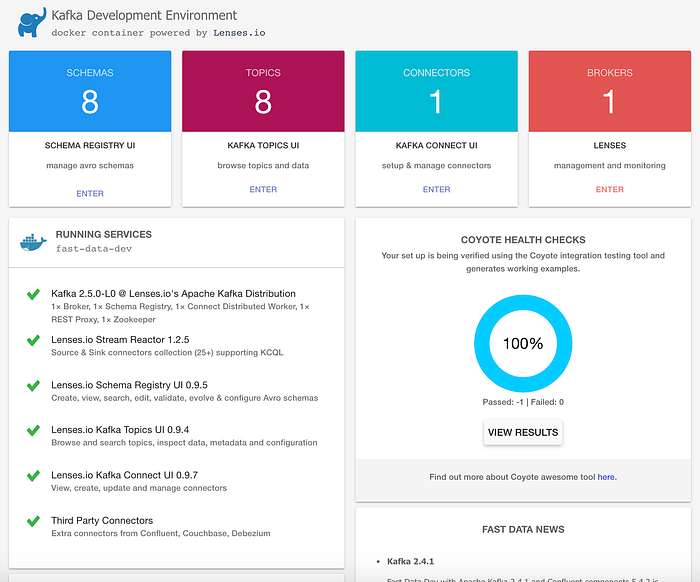
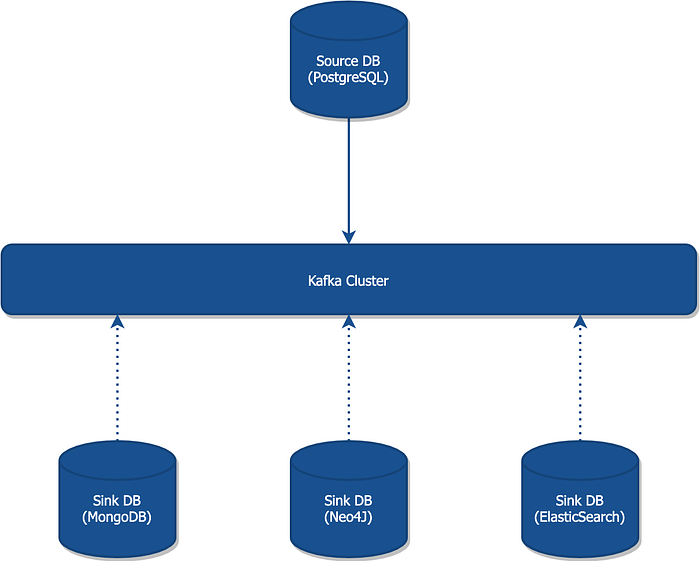
That’s it! With this setup you’re able to handle from few messages up to billions of messages per day. It’s prepared to scale up horizontally or even to move to a different machine later on since it’s taking advantage of Kafka Connect’s distributed mode. Moreover, with Kafka acting as backbone, you can use it as a central integration point for numerous data sinks like Neo4j, MongoDB, ElasticSearch and so on:
Final thoughts
As you could see, it can be easy to setup your data pipeline by choosing the right tools. You don’t need to have a deep knowledge about Kafka and Zookeeper configurations to start using Kafka Connect nor you need to spend hours and hours trying to understand how to put all of these tools working together. By following this approach you’ll be on the right path to provide a great infrastructure while focusing on your biggest concern: data.
You can find all the necessary configurations on the following repository.
